import numpy as np
import xarray as xr
import matplotlib.pyplot as plt
rng = np.random.default_rng(42)
lats_f = np.arange(25, 50, 0.25)
lons_f = np.arange(-120, -70, 0.25)
LON, LAT = np.meshgrid(lons_f, lats_f)
storm = 20 * np.exp(-((LAT-38)**2/4 + (LON+100)**2/4))
precip = storm + 1.0 + rng.exponential(0.5, storm.shape)
ds_fine = xr.Dataset({'precip': (['lat','lon'], precip, {'units':'mm/day'})},
coords={'lat': lats_f, 'lon': lons_f})
lats_c = np.arange(25.5, 50, 1.0)
lons_c = np.arange(-119.5, -70, 1.0)
ds_nn = ds_fine.sel(lat=lats_c, lon=lons_c, method='nearest')
ds_bil = ds_fine.interp(lat=lats_c, lon=lons_c)
# Manual conservative (exact area-integral normalization, all in radians)
def block_conservative(ds_src, lats_tgt, lons_tgt, src_dlat=0.25, src_dlon=0.25):
out = np.zeros((len(lats_tgt), len(lons_tgt)))
tgt_dlat = abs(lats_tgt[1] - lats_tgt[0]) if len(lats_tgt) > 1 else 1.0
tgt_dlon = abs(lons_tgt[1] - lons_tgt[0]) if len(lons_tgt) > 1 else 1.0
for j, lt in enumerate(lats_tgt):
for i, ln in enumerate(lons_tgt):
mask_lat = (ds_src.lat >= lt - tgt_dlat/2) & (ds_src.lat < lt + tgt_dlat/2)
mask_lon = (ds_src.lon >= ln - tgt_dlon/2) & (ds_src.lon < ln + tgt_dlon/2)
sub = ds_src['precip'].isel(lat=mask_lat, lon=mask_lon)
fine_lats = ds_src.lat.values[mask_lat]
if sub.size > 0:
# Fine cell areas in steradians: cos(lat) * dlat_rad * dlon_rad
fine_areas = (np.cos(np.radians(fine_lats)) *
np.radians(src_dlat) * np.radians(src_dlon))[:, None]
# Coarse cell area: exact integral of cos(lat) dlat dlon (all radians)
coarse_area = ((np.sin(np.radians(lt + tgt_dlat/2))
- np.sin(np.radians(lt - tgt_dlat/2)))
* np.radians(tgt_dlon))
out[j, i] = np.sum(sub.values * fine_areas) / coarse_area
return out
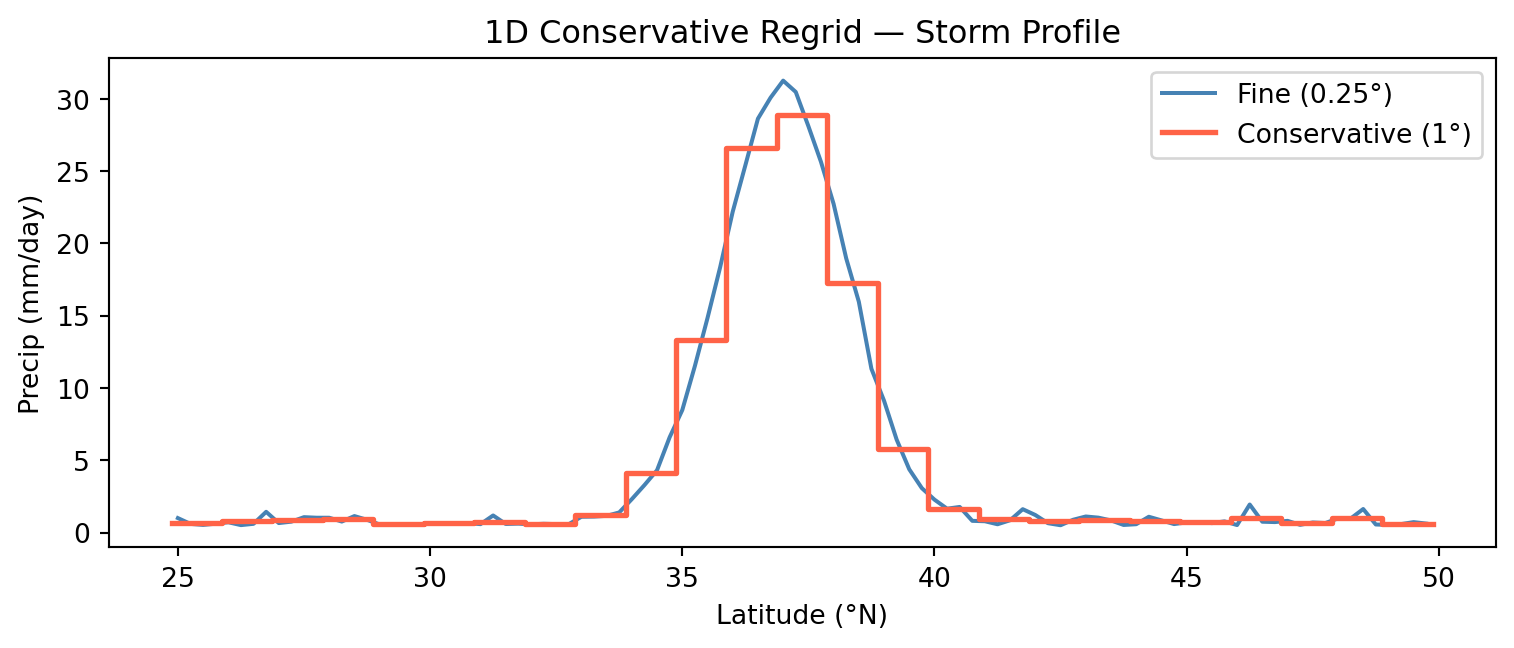
cons_vals = block_conservative(ds_fine, lats_c, lons_c)
ds_cons = xr.Dataset({'precip': (['lat','lon'], cons_vals, {'units':'mm/day'})},
coords={'lat': lats_c, 'lon': lons_c})
# Cell area proportional to cos(lat) * dlat * dlon — must include grid spacing or
# the fine grid (16× more cells) will give a 16× larger domain sum.
dlat_f, dlon_f = 0.25, 0.25
dlat_c, dlon_c = 1.0, 1.0
w_f = np.cos(np.radians(ds_fine.lat)) * dlat_f * dlon_f
w_c = np.cos(np.radians(ds_nn.lat)) * dlat_c * dlon_c
t_fine = float((ds_fine['precip'] * w_f).sum())
t_nn = float((ds_nn['precip'] * w_c).sum())
t_bil = float((ds_bil['precip'] * w_c).sum())
t_cons = float((ds_cons['precip'] * w_c).sum())
print(f"{'Method':<20} {'Total':>10} {'Error':>12} {'Peak':>10}")
print("-" * 56)
print(f"{'Fine (0.25°)':<20} {t_fine:>10.1f} {'—':>12} {float(ds_fine['precip'].max()):>10.2f}")
print(f"{'Nearest (1°)':<20} {t_nn:>10.1f} {(t_nn-t_fine)/t_fine*100:>10.2f}% {float(ds_nn['precip'].max()):>10.2f}")
print(f"{'Bilinear (1°)':<20} {t_bil:>10.1f} {(t_bil-t_fine)/t_fine*100:>10.2f}% {float(ds_bil['precip'].max()):>10.2f}")
print(f"{'Conservative (1°)':<20} {t_cons:>10.1f} {(t_cons-t_fine)/t_fine*100:>10.4f}% {float(ds_cons['precip'].max()):>10.2f}")