Mon 15.2
Tue 18.7
Wed 22.1
Thu 19.8
dtype: float64ATOC 4815/5815
Tabular Data & Pandas Foundations - Week 7
Spring 2026
Reminders
Due this evening at 12pm:
- Lab 4
Office Hours:
Will: Tu 11:15-12:15p; Th 9-9:50a
Aerospace Cafe
Aiden: M / W 330-430p
DUAN D319
ATOC 4815/5815 Playlist

Rolling Window Visualization
import matplotlib.pyplot as plt
# Plot raw data and rolling means
plt.figure(figsize=(9, 4))
plt.plot(temps.index, temps, alpha=0.3, label='Raw (hourly)', linewidth=1)
plt.plot(temps.index, temps_3h, label='3-hour rolling mean', linewidth=1.5)
plt.plot(temps.index, temps_12h, label='12-hour rolling mean', linewidth=1.5)
plt.plot(temps.index, temps_24h, label='24-hour rolling mean', linewidth=2)
plt.xlabel('Date')
plt.ylabel('Temperature (°C)')
plt.title('Temperature with Rolling Means')
plt.legend()
plt.grid(True, alpha=0.3)
plt.tight_layout()
plt.show()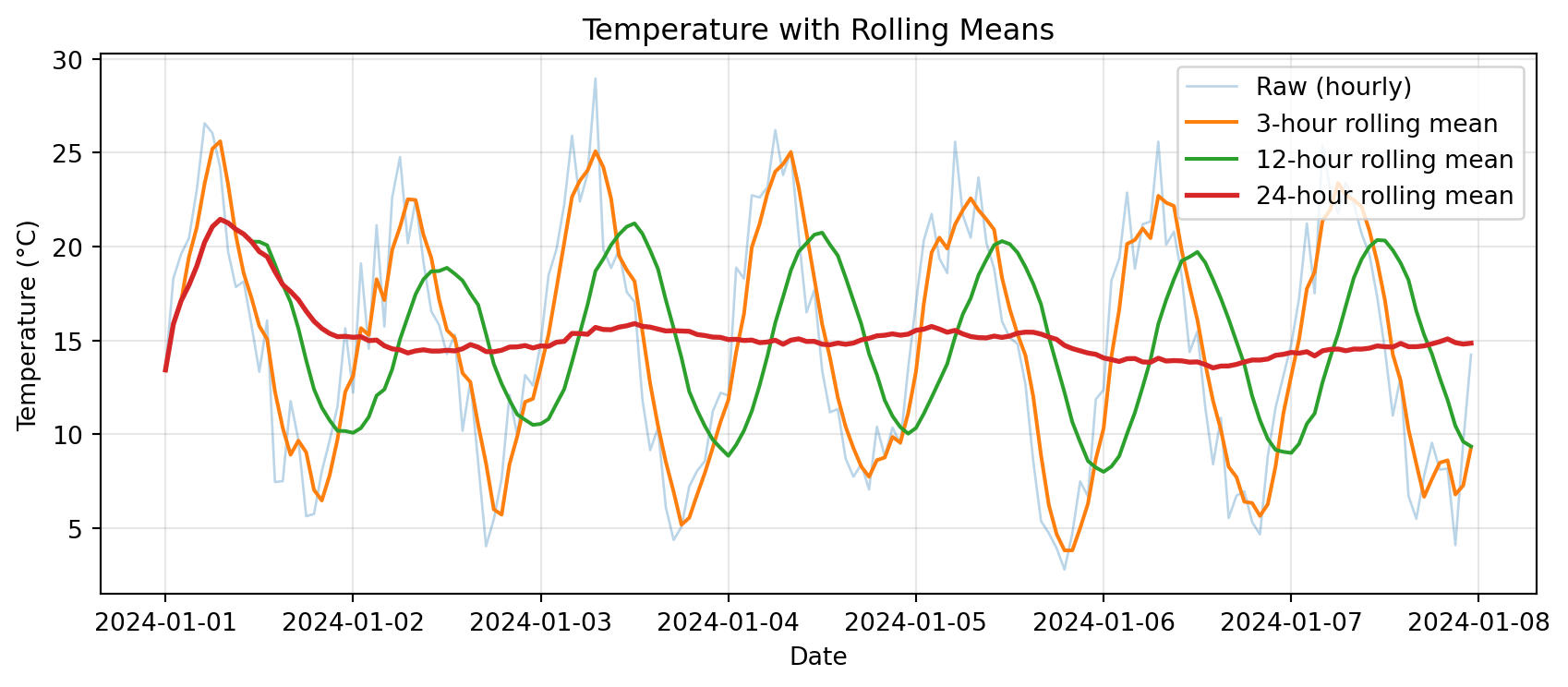
Notice: Longer windows → smoother curves, but more lag
Use Case: Temperature Variability
Rolling standard deviation shows how variable conditions are:
# Create data with changing variability
dates = pd.date_range('2024-01-01', periods=168, freq='h')
# Add more noise in second half
noise = np.concatenate([
np.random.randn(84) * 1, # Low variability
np.random.randn(84) * 4 # High variability
])
temps = pd.Series(
15 + 8 * np.sin(np.arange(168) * 2 * np.pi / 24) + noise,
index=dates
)
rolling_mean = temps.rolling('12h').mean()
rolling_std = temps.rolling('12h').std()
# Plot
fig, (ax1, ax2) = plt.subplots(2, 1, figsize=(9, 5), sharex=True)
ax1.plot(temps.index, temps, alpha=0.4, label='Hourly temp')
ax1.plot(temps.index, rolling_mean, linewidth=2, label='12-h mean')
ax1.set_ylabel('Temperature (°C)')
ax1.set_title('Temperature and Variability')
ax1.legend()
ax1.grid(True, alpha=0.3)
ax2.plot(temps.index, rolling_std, color='red', linewidth=2)
ax2.set_xlabel('Date')
ax2.set_ylabel('Rolling Std Dev (°C)')
ax2.set_title('12-hour Rolling Variability')
ax2.grid(True, alpha=0.3)
plt.tight_layout()
plt.show()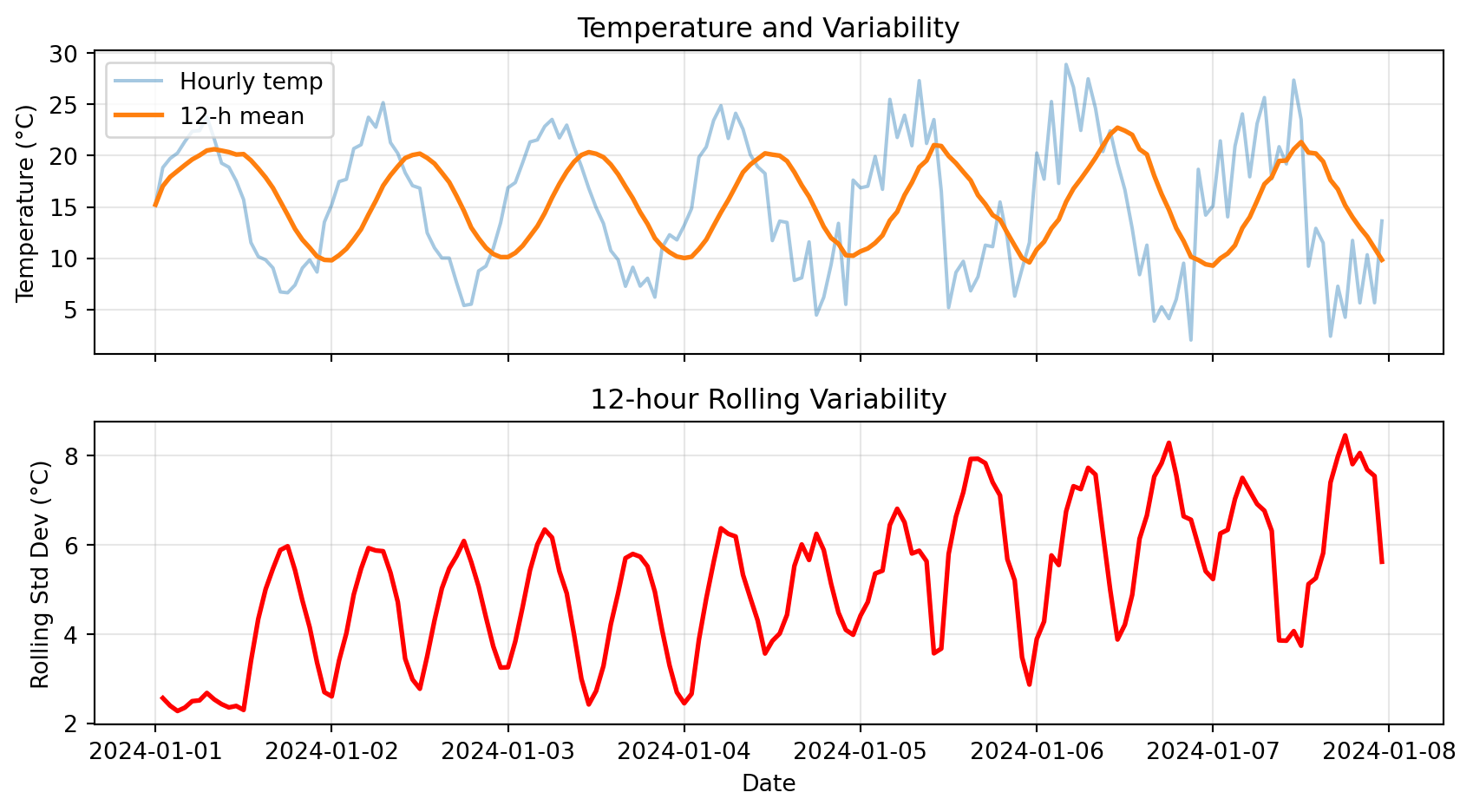
Notice: High rolling std in second half → more variable conditions
Visualizing Anomalies
# Plot raw data and anomalies
fig, (ax1, ax2) = plt.subplots(2, 1, figsize=(9, 5), sharex=True)
# Top: Raw temperature
ax1.plot(df.index, df['temp_c'], label='Hourly temp', alpha=0.7)
ax1.plot(df.index, df['daily_mean'], label='Daily mean', linewidth=2, color='red')
ax1.set_ylabel('Temperature (°C)')
ax1.set_title('Raw Temperature and Daily Mean')
ax1.legend()
ax1.grid(True, alpha=0.3)
# Bottom: Anomalies
ax2.plot(df.index, df['anomaly'], color='purple', alpha=0.7)
ax2.axhline(y=0, color='black', linestyle='--', linewidth=1)
ax2.set_xlabel('Date')
ax2.set_ylabel('Anomaly (°C)')
ax2.set_title('Hourly Anomalies from Daily Mean')
ax2.grid(True, alpha=0.3)
plt.tight_layout()
plt.show()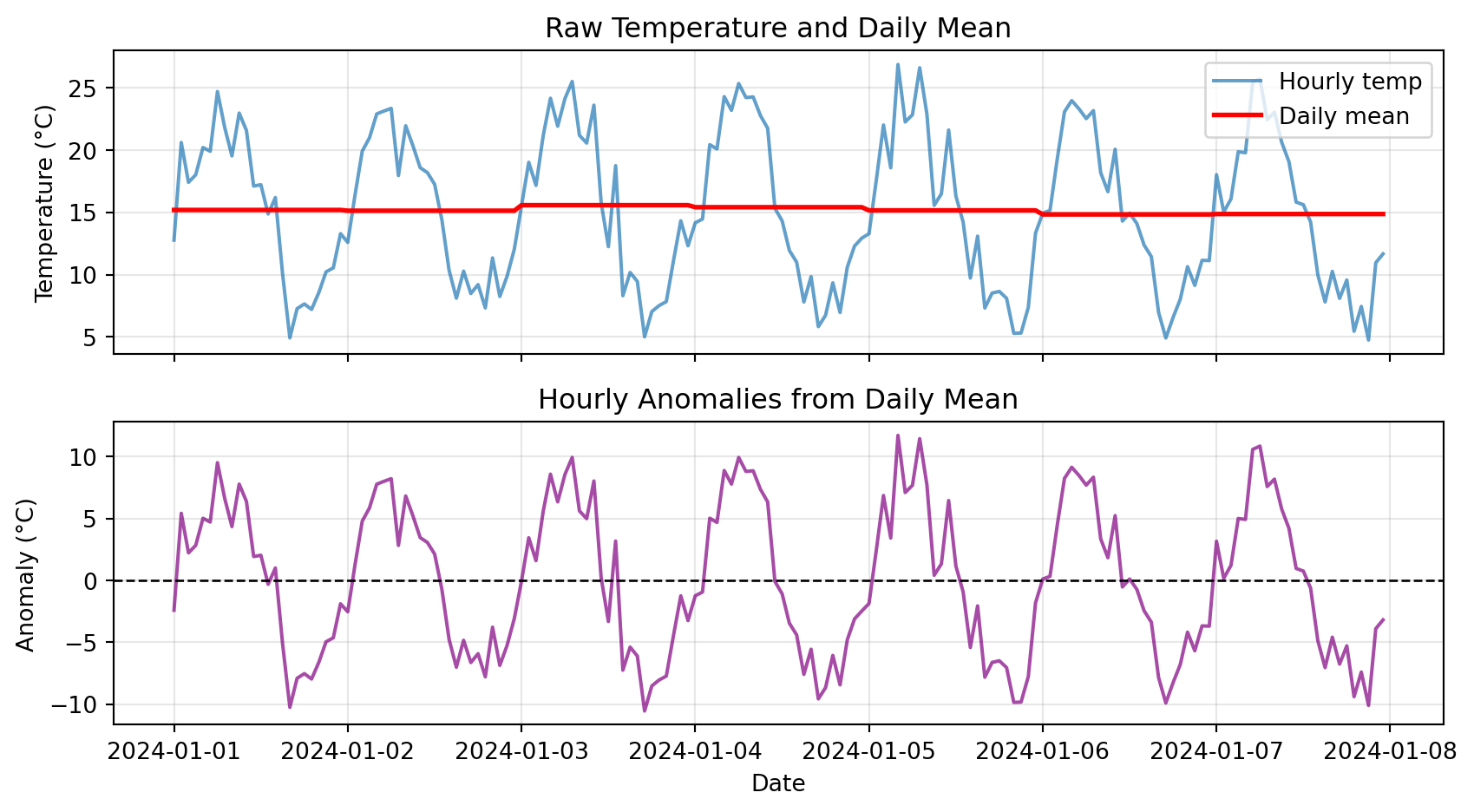
Notice: Anomalies oscillate around zero, showing deviations from typical pattern
Cumulative Precipitation Visualization
# Plot hourly and cumulative
fig, (ax1, ax2) = plt.subplots(2, 1, figsize=(9, 5), sharex=True)
# Top: Hourly bars
ax1.bar(precip.index, precip, width=0.04, alpha=0.6, color='steelblue')
ax1.set_ylabel('Hourly Precip (mm)')
ax1.set_title('Hourly Precipitation')
ax1.grid(True, alpha=0.3)
# Bottom: Cumulative line
ax2.plot(cumulative.index, cumulative, linewidth=2, color='darkblue')
ax2.set_xlabel('Date')
ax2.set_ylabel('Cumulative Precip (mm)')
ax2.set_title('Cumulative Precipitation')
ax2.grid(True, alpha=0.3)
plt.tight_layout()
plt.show()
print(f"\nTotal precipitation over week: {cumulative.iloc[-1]:.2f} mm")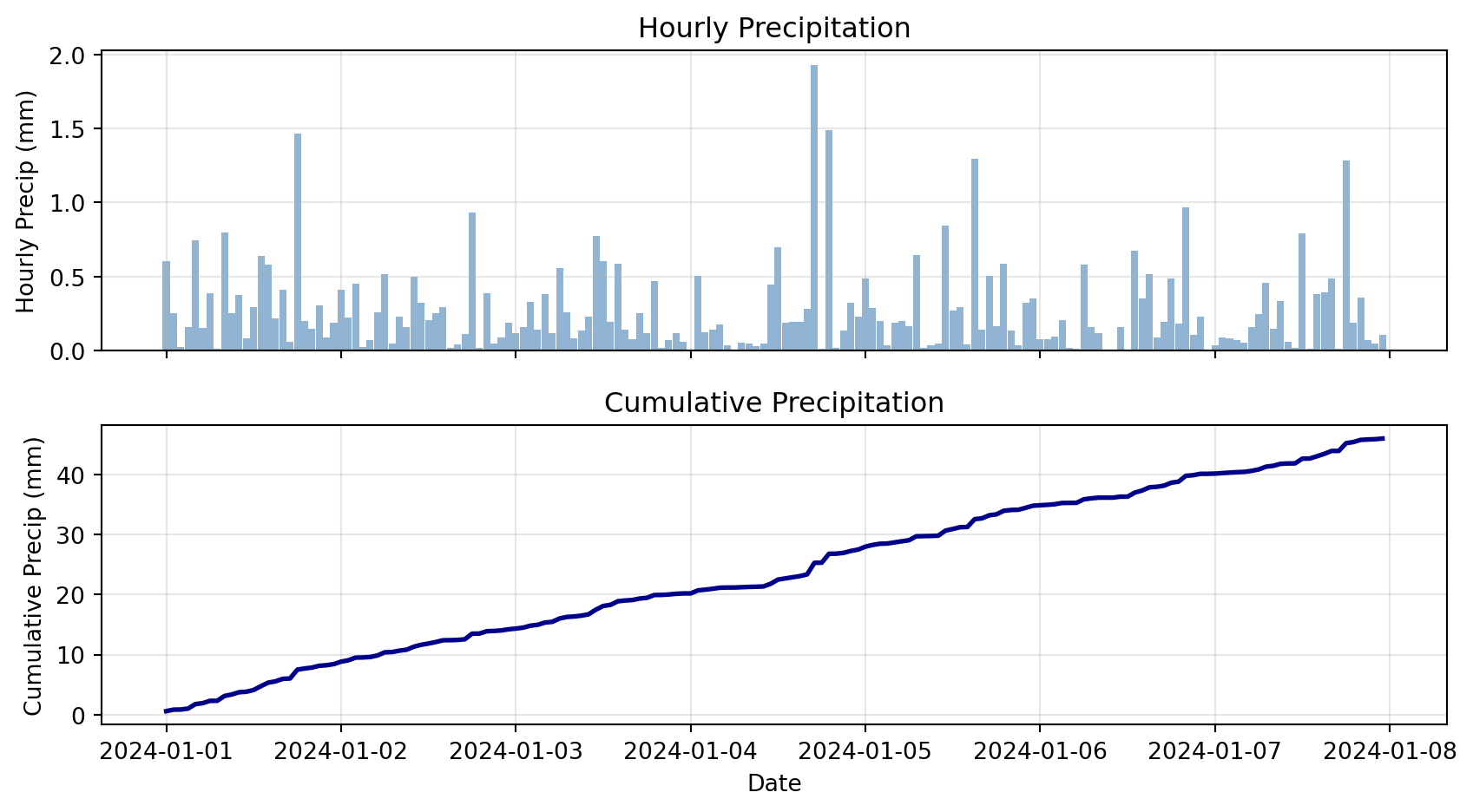
Total precipitation over week: 50.02 mmPandas Native Plotting
Pandas DataFrames have built-in .plot() method:
# Create sample data
dates = pd.date_range('2024-01-01', periods=168, freq='h')
df_plot = pd.DataFrame({
'temp_c': 15 + 8 * np.sin(np.arange(168) * 2 * np.pi / 24) + np.random.randn(168) * 2,
}, index=dates)
df_plot['rolling_24h'] = df_plot['temp_c'].rolling('24h').mean()
# Simple plot
df_plot.plot(
figsize=(9, 4),
title='Temperature Time Series',
ylabel='Temperature (°C)',
grid=True,
alpha=0.7
)
plt.tight_layout()
plt.show()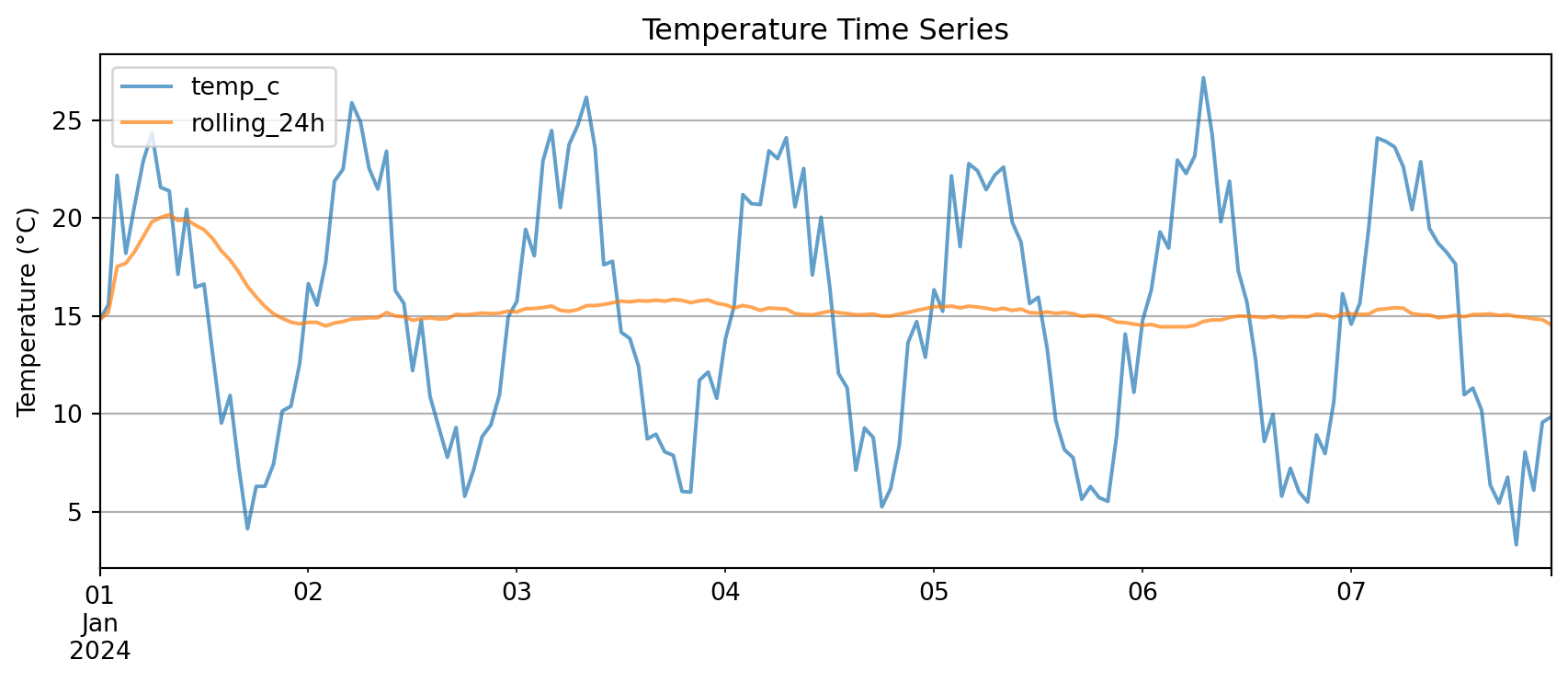
Key advantage: .plot() automatically uses the index as x-axis
Multi-Panel Time Series
For complex analysis, use matplotlib subplots:
# Create comprehensive dataset
dates = pd.date_range('2024-01-01', periods=168, freq='h')
weather = pd.DataFrame({
'temp_c': 15 + 8 * np.sin(np.arange(168) * 2 * np.pi / 24) + np.random.randn(168) * 2,
'rh_pct': 60 + 20 * np.sin(np.arange(168) * 2 * np.pi / 24 + np.pi/4) + np.random.randn(168) * 5,
'precip_mm': np.random.exponential(0.3, 168)
}, index=dates)
# Add derived quantities
weather['temp_rolling_24h'] = weather['temp_c'].rolling('24h').mean()
weather['cumulative_precip'] = weather['precip_mm'].cumsum()
# Create multi-panel plot
fig, (ax1, ax2, ax3) = plt.subplots(3, 1, figsize=(9, 7), sharex=True)
# Panel 1: Temperature
ax1.plot(weather.index, weather['temp_c'], alpha=0.4, label='Hourly Temp')
ax1.plot(weather.index, weather['temp_rolling_24h'], linewidth=2, label='24-h Rolling Mean')
ax1.set_ylabel('Temperature (°C)')
ax1.set_title('Weather Time Series Analysis')
ax1.legend(loc='best')
ax1.grid(True, alpha=0.3)
# Panel 2: Relative Humidity
ax2.plot(weather.index, weather['rh_pct'], color='green', alpha=0.7)
ax2.set_ylabel('Relative Humidity (%)')
ax2.grid(True, alpha=0.3)
# Panel 3: Precipitation (dual y-axes)
ax3.bar(weather.index, weather['precip_mm'], width=0.04, alpha=0.6, label='Hourly Precip')
ax3_cum = ax3.twinx()
ax3_cum.plot(weather.index, weather['cumulative_precip'], color='steelblue',
linewidth=2, label='Cumulative')
ax3.set_xlabel('Date')
ax3.set_ylabel('Hourly Precip (mm)')
ax3_cum.set_ylabel('Cumulative (mm)')
ax3.legend(loc='upper left')
ax3_cum.legend(loc='upper right')
ax3.grid(True, alpha=0.3)
plt.tight_layout()
plt.show()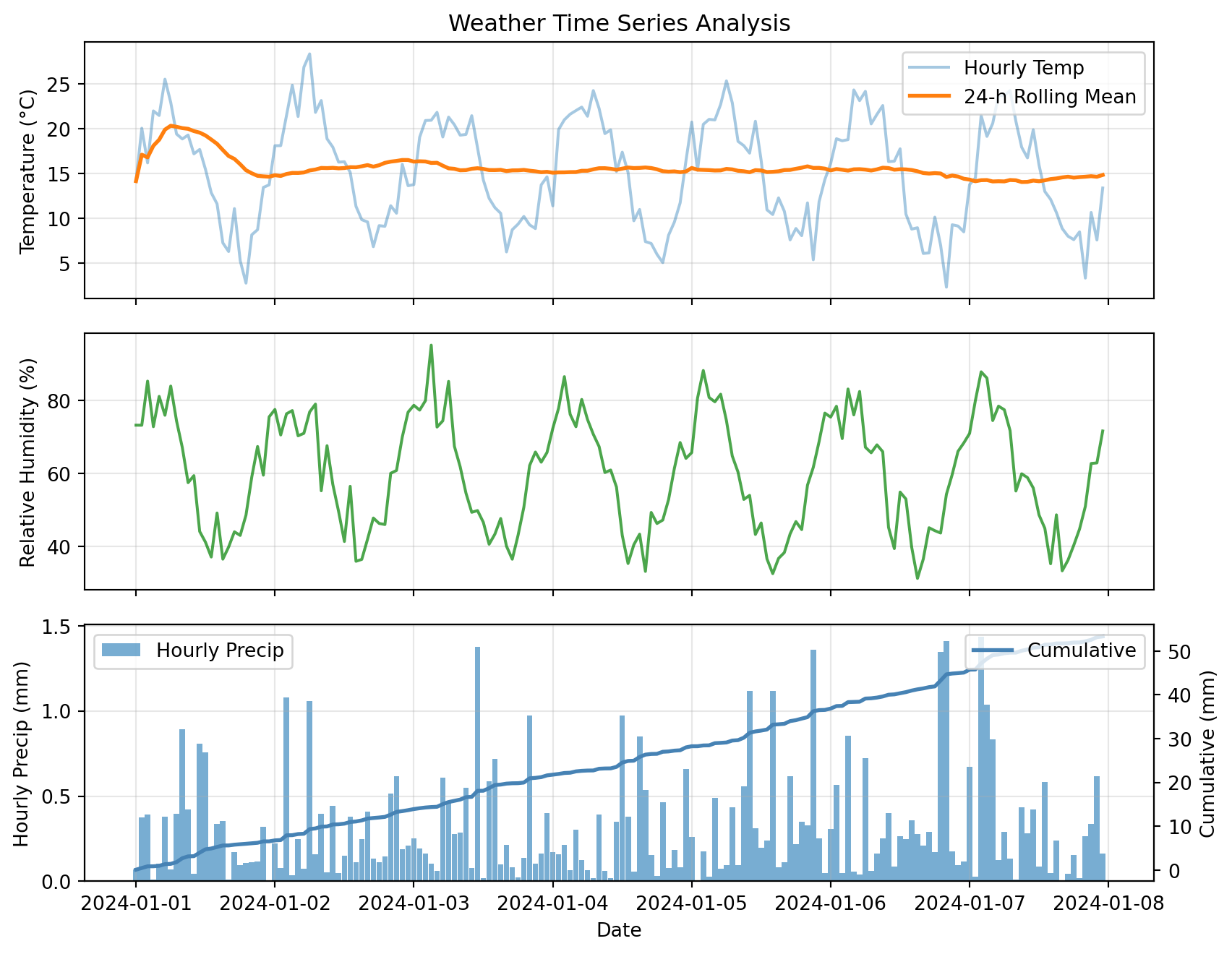
This plot combines:
- Raw and smoothed time series (top)
- Secondary variables (middle)
- Dual y-axes for different scales (bottom)
